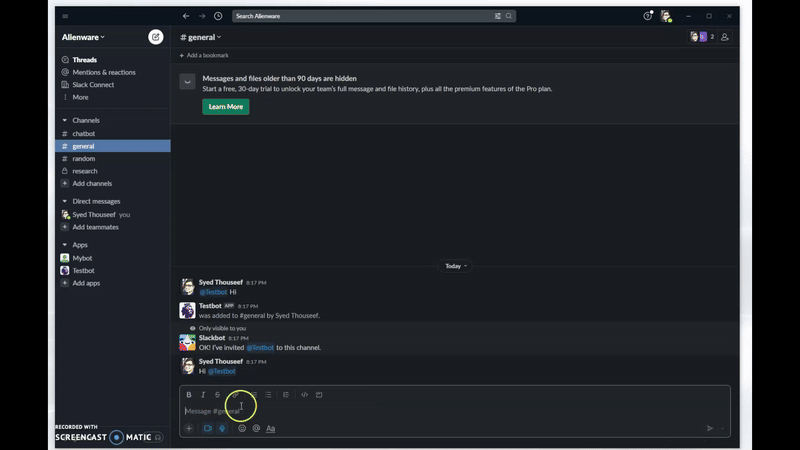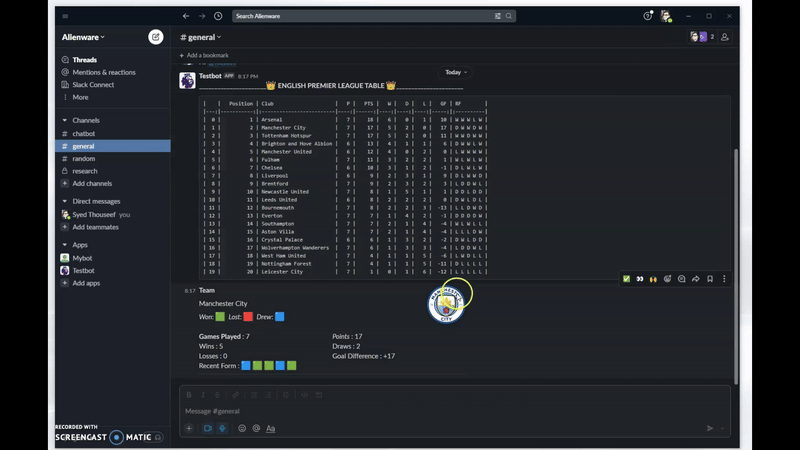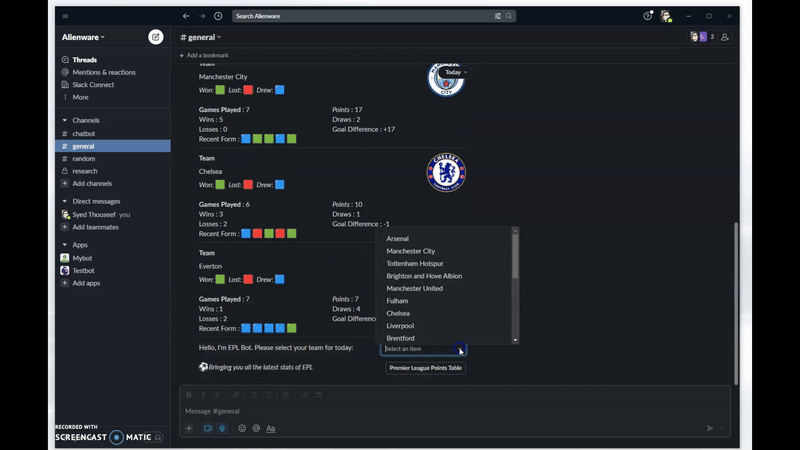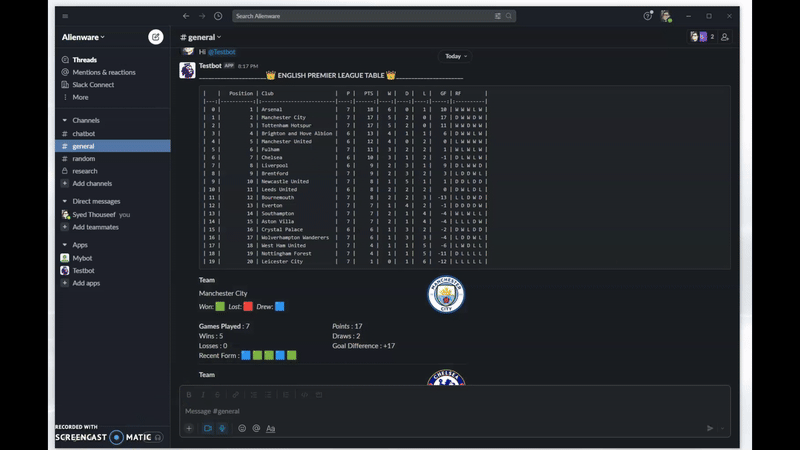
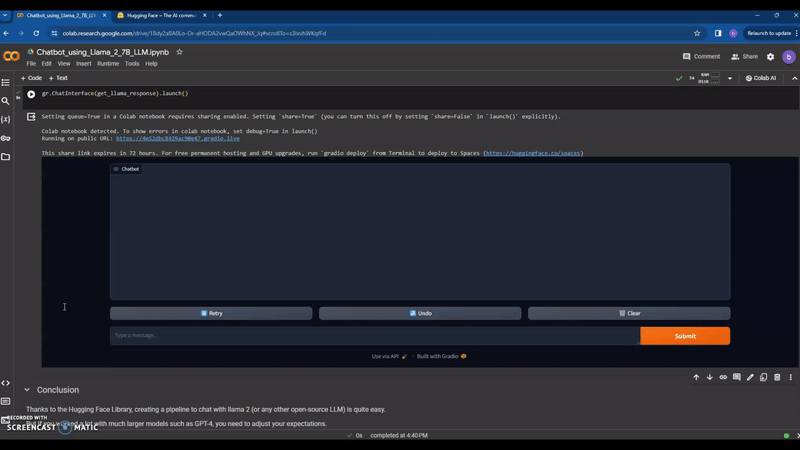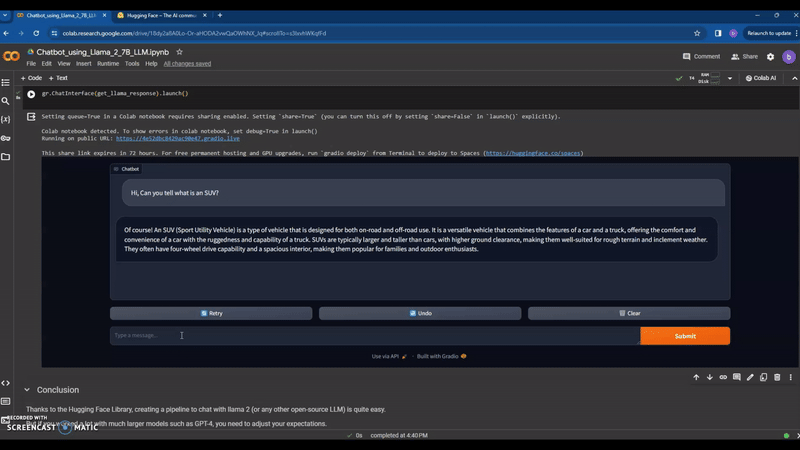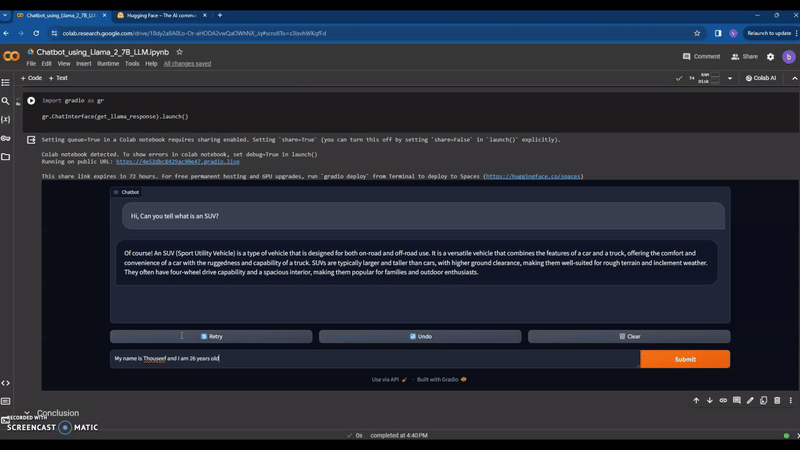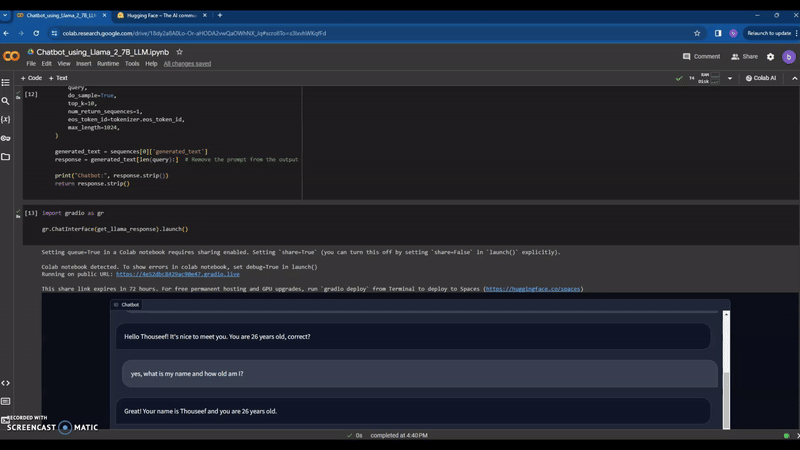
I am Thouseef Syed,
Chatbot Developer Machine Learning Researcher GenAI Developer Computational Modeling NLP Computer Vision Speech Recognition IoT Systems
Introduction
I'm a Principal AI & Chatbot Engineer with 7+ years of experience designing, architecting, and deploying Agentic AI systems using LLMs, Model Context Protocol (MCP), RAG pipelines, NLP/NLG, and orchestration frameworks. Proven expertise in building multi-agent, enterprise-ready AI solutions that drive measurable business impact across customer experience, automation, and decision intelligence.
Skilled in Generative AI, Machine Learning, and agentic automation frameworks, with hands-on leadership across the full lifecycle—research, design, integration, deployment, and scaling. Experienced in knowledge orchestration, autonomous agent workflows, and tool integrations, consistently aligning AI initiatives with organizational goals. Published researcher in Applied Cognition & Neuroscience, combining deep technical expertise with cross-functional collaboration and stakeholder engagement to deliver scalable, responsible, and high-impact AI solutions.
Education
Masters of Science | The University of Texas at Dallas
Major : Applied Cognition & Neuroscience, specialized in
Computational modeling and Artificial Intelligence (AI)
& Machine Learning (ML)
Bachelor of Science | PES Institute of Technology
Major : Electronics & Communication Engineering
Projects
Older Projects
IoT Based Generalized Object
Tracking System
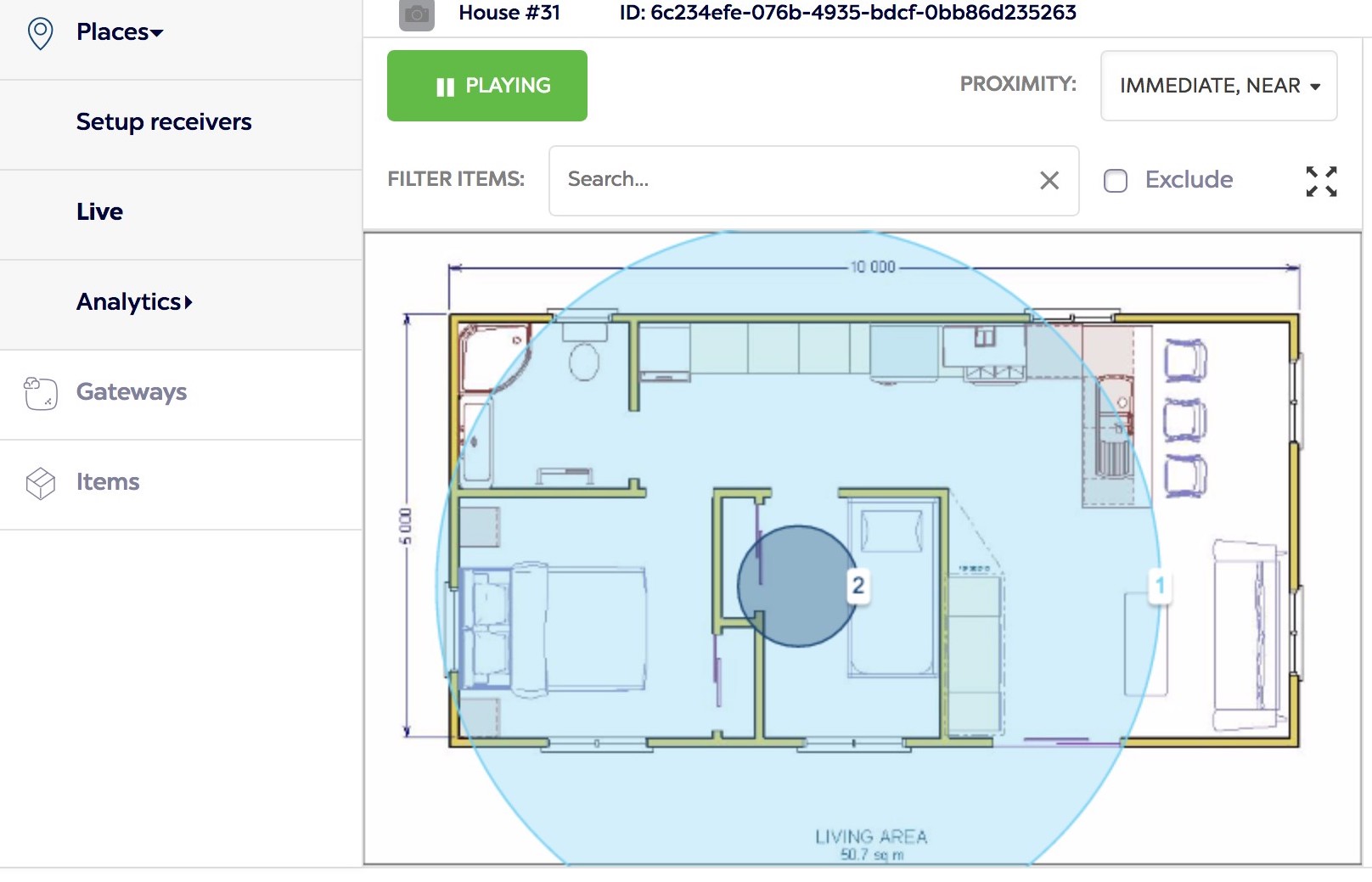
IoT based generalized object tracking system uses the concept of Bluetooth Low
Energy. Beacons based on BLE are mounted on the objects that are to be tracked
and a gateway is deployed in the region of interest. This is an interface between the
cloud service, app (or web panel) and beacons. On a given floor map the beacons can
be localized with the help of the gateway, in broadly three categories - immediate,
near and far.
Image Classification on CIFAR-100 dataset using CNN
Implementation of an image recognition model that identifies distinctive objects using convolutional and max pooling layers.
An Interactive Object Recognition Tool : A Deep Learning Approach
Object Recognition has recently become one of the most exciting fields in computer vision and AI. The ability of immediately recognizing all the objects in a scene seems to be no longer a secret of evolution. With the development of Convolutional Neural Network architectures, backed by big training data and advanced computing technology, a computer now can surpass human performance in object recognition task under some specific settings, such as face recognition.
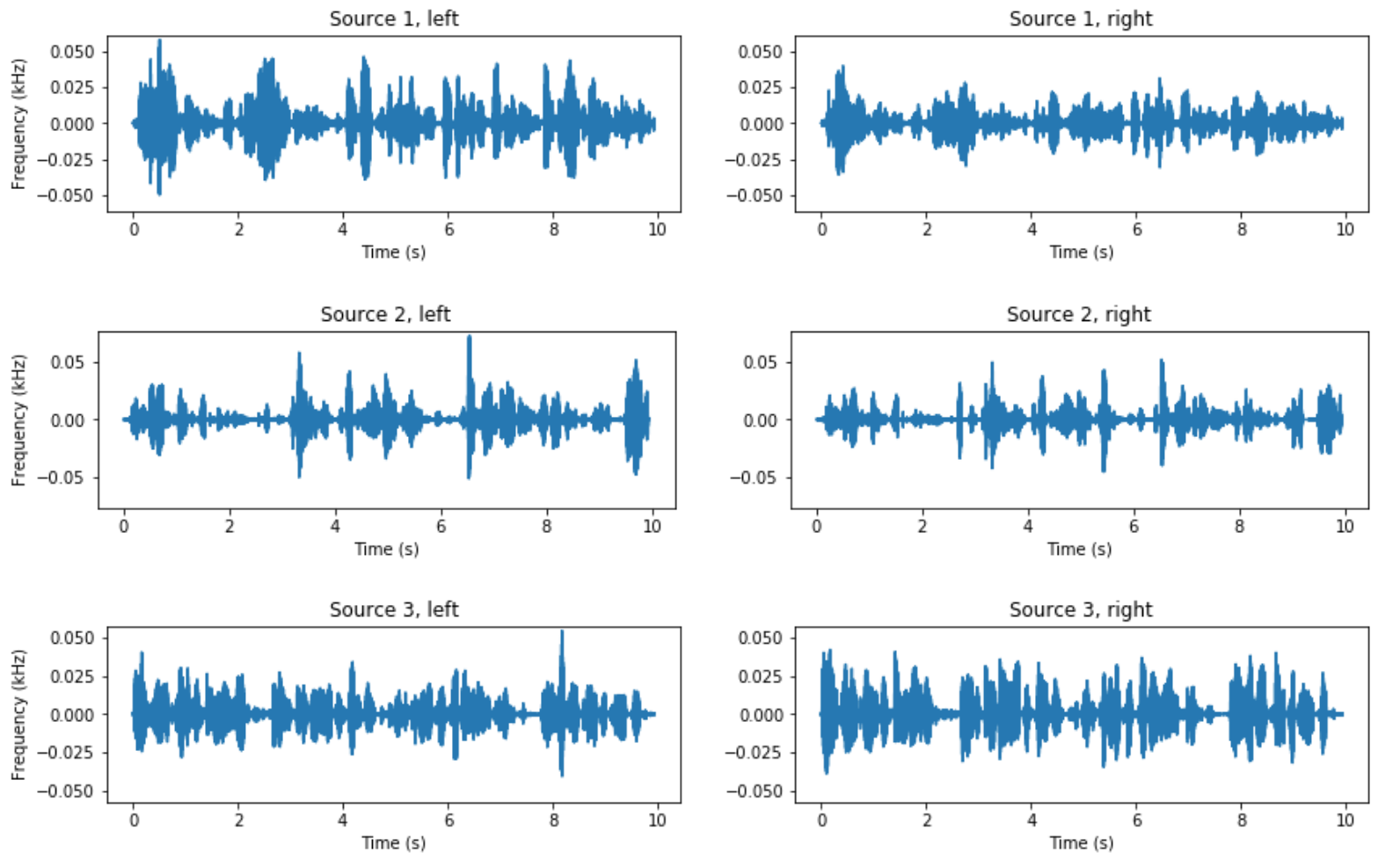
Towards Unsupervised Auditory Scene Analysis : Blind Source Separation using Non-Negative Matrix Factorization Methods
The world is full of noise, and the auditory environment is rarely simple, clean, and from clearly distinct sound sources. The cocktail party problem highlights this as a blind source separation problem where a scene can be separate concurrent speech signals drowned in a word of many sounds. While the brain can handle such a task fairly well, finding the computational equivalent requires testing many algorithms. This paper works specifically as an exploration of the GCC-NMF algorithm which combines negative matrix factorization (NMF) for unsupervised dictionary learning and generalized cross correlation (GCC) for spatial localization. Our work extends the algorithm by applying more source data, especially ones that are not necessarily speech signals. Results were similar to past work and shows high efficacy and accuracy across various sources. Eventually the goal is to apply classification after the separation with the goal to find patterns. Being able to compare the algorithm via factors such as target fidelity and lack of sound artifacts and ultimately pinpointing its strengths should lead to a better understanding of blind source separation. Higher efficacy for separation will benefit basic audio processing to work on assistive hearing devices and speech recognition systems.
Hi, my name is BESSO. I’m your virtual lab assistant that specialises in providing academic, research, innovation, technical and admin support to the users.
A brief introduction of my species:
A virtual assistant, also called AI assistant or digital assistant, is an application program that understands natural language voice commands and completes tasks for the user.
Object recognition using Single Shot Multibox Detection
This is currently an ongoing project, further details will be provided in a few weeks.
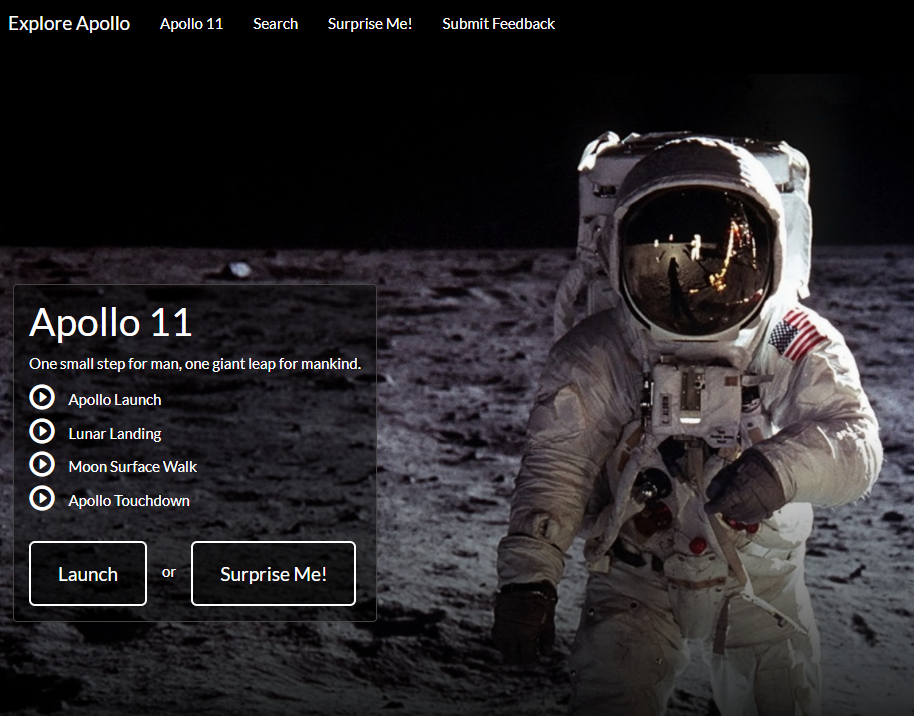
Speaker ID on Apollo 11 corpus: A Study using different Machine Learning Models
The main goal here was to match a voice sample from an unknown speaker to one of several labeled speaker models since speech is easily produced. For the feature extraction, Mel Frequency Cepstrum Coefficients was used since it is one of the most common features used for speaker recognition. Before extracting the features, we performed pre-processing such as Voice Activity detection to ignore unvoiced parts of the speech. For classification and objective comparison, K-Nearest Neighborhood (KNN), Convolutional Neural Network (CNN) and I-vectors/PLDA results was shared. The dataset used for the project is FEARLESS STEPS that consists of 10 hours of digitized recordings of the Apollo 11 Space Mission. These recordings were digitized by the Centre of Robust Speech Systems (CRSS) of The University of Texas at Dallas. It was typically used for speech activity detection, sentiment analysis and speaker recognition. In the research, there were a few challenges that were met using methods. Our main focus will be detecting speech parts of the speech signals and classifying the respective speakers in the given time frame.
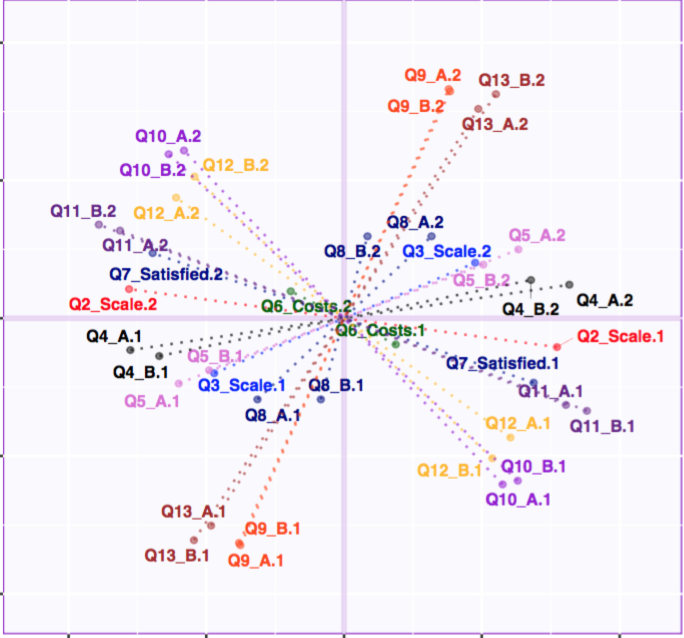
Research Methods: Multivariate Analysis on Driving Style using R
This book highlights the multitude of factors that influence the driving style of experienced drivers. For the purpose of this study, analytical methods like Principal Component Analysis (PCA), Correspondence Analysis (CA), Multiple Component Analysis (MCA), Partial Least Square Correltion (PLSC), Multiple Factor Analysis (MFA) and many more were used. It was observed that few key factors played a major role in influencing the drivers in many occasions.